
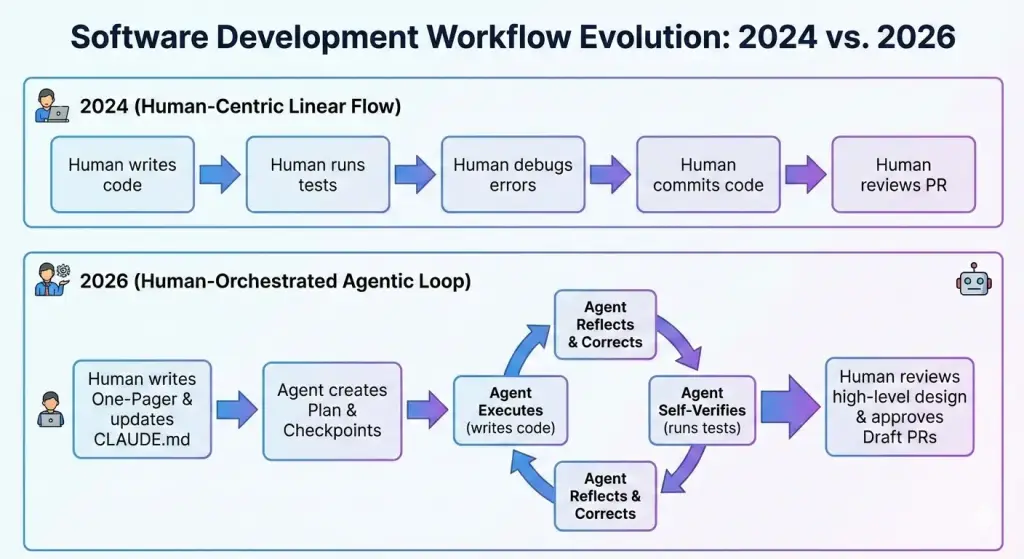
Over the past two years, my day-to-day work has shifted from direct implementation toward orchestration and verification. In early 2024, I used AI mostly for autocomplete-level tasks such as snippets, error explanations, and small refactors. By 2026, I still write code when needed, but far more of my time goes to defining tasks clearly, checking outputs, and fixing edge cases the agents miss.
2024
I started experimenting with Cline for straightforward tasks such as boilerplate, test scaffolding, and repetitive refactors. I avoided giving it larger tasks for two reasons. First, it was easy to get code that looked fine but was wrong in non-obvious ways. Second, anything non-trivial took too much prompt back-and-forth.
2025
I switched to Claude Code and stopped asking for immediate implementation. Instead, I asked for a plan first and reviewed it.
That improved outcomes, but two problems stayed persistent. Plans were often overbuilt for the actual problem, and the agent would report "done" before handling edge cases. The bottleneck moved from writing code to verification.
What made the workflow more reliable
Three changes made the workflow dependable enough for daily use.
Stronger model reasoning
For my use cases, newer models (especially Opus 4.5) were noticeably better at keeping constraints in context across longer tasks.
Better repo context
A lot of bad output came from missing context, not missing capability. I now keep project expectations in CLAUDE.md so every new session starts with the same baseline: architecture preferences, testing requirements, and coding conventions.
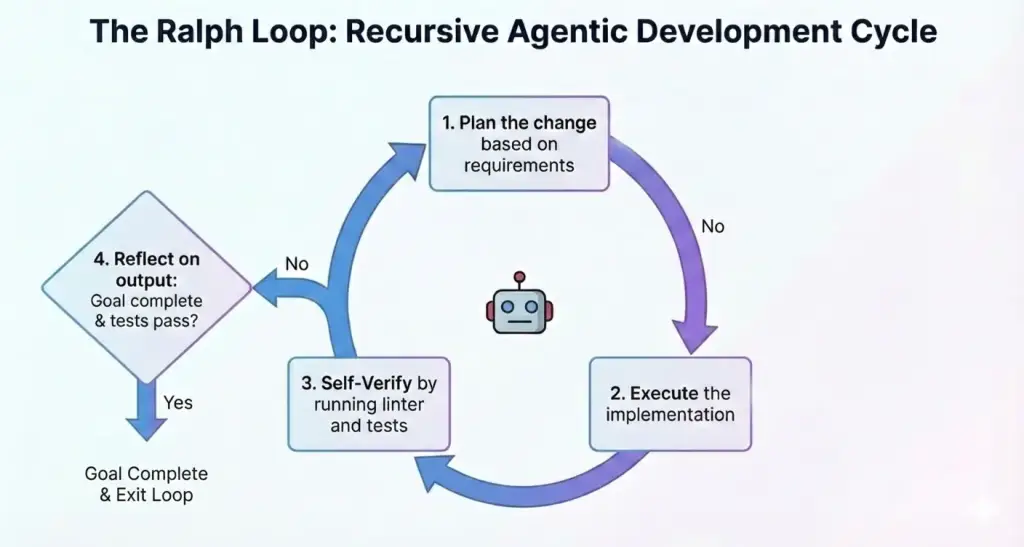
A repeatable execution loop
The biggest improvement was switching from one-pass execution to a repeatable loop:
- Plan
- Implement
- Verify with build/lint/tests
- Reflect and continue if needed
Current workflow
I usually run a planner and an implementer in parallel. In practice, that means I write a short feature brief with constraints and non-goals, turn that into checkpoints, let the implementer run the loop per checkpoint, and then review design and risk rather than just syntax.
Example brief:
Add Google OAuth using existing
AuthService. Store tokens in Redis, not SQL.
Trade-offs
This workflow is productive, but it has clear costs:
- Cost: Frequent tool calls and retries add up quickly.
- Legacy code friction: Agents struggle when systems rely on undocumented history.
- Personal skill drift: I type less code directly than I used to.
- Attention overhead: Running multiple agents sounds parallel, but review and coordination still funnel through one person. Human attention is limited, and I still don't have a great system for managing that bottleneck consistently.
Where the work moved
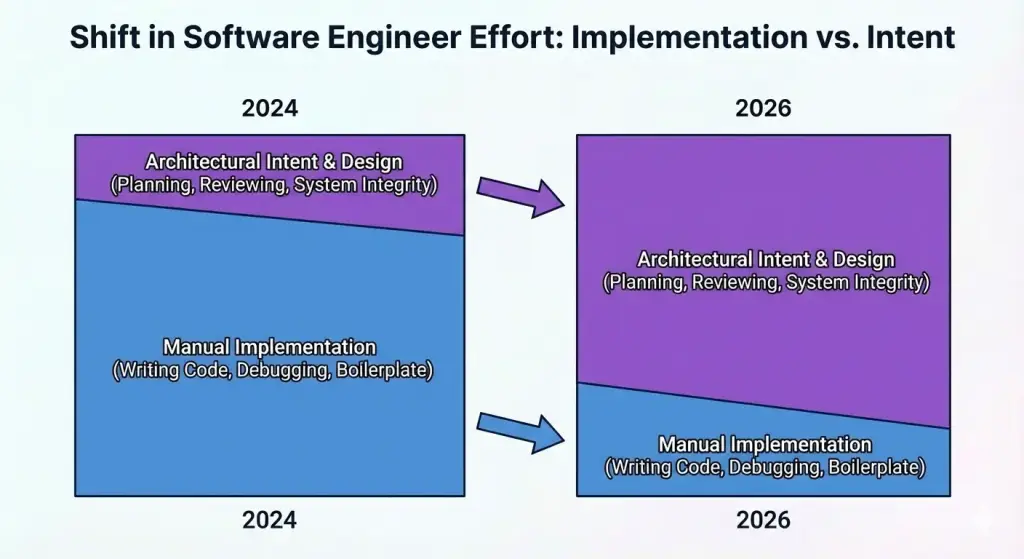
The useful part of my work has moved toward clearer requirements, tighter constraints, and stronger review discipline.
Implementation still matters, but the highest leverage is in deciding what should be built and verifying whether the output is actually correct.
The biggest open question for me is this: if newer engineers spend less time in low-level debugging, how do they build the judgment needed to review AI-generated changes well?
Get new posts by email
Subscribe for occasional updates when I publish something new.
Related posts
Everyone Is a Builder Now
February 28, 2026
Over cocktails, my colleagues and I talked about why AI lowering the barrier to building is a net positive.
Relearning Through Small Interactive Tools
April 10, 2026
Using a coding agent to build small browser tools turned out to be a good way to revisit concepts I had not touched in a while.
Making Responsive Images Just Work
March 4, 2026
Instead of manually managing -sm/-md/-lg assets, I moved to a manifest-driven workflow that reduced duplication and made performance outcomes more consistent.